电商网站商品数据分析是提升运营效率、洞察行业趋势和优化决策流程的关键环节。 很多电商从业者都会遇到以下难题:
本文将围绕这些实际痛点,结合Python数据分析实操案例,深入拆解电商商品数据分析的方法论与技术实现路径。你将收获:
如果你想用技术手段让商品管理、销售预测、财务核算和库存调度变得更高效、更智能,这篇文章就是你的实战指南。
电商网站商品数据分析的本质,是通过对商品相关数据的多维度采集、整理、建模和解读,驱动运营优化和业务增长。 在实际电商运营中,数据分析不是单纯的数字统计,而是业务逻辑与数据技术深度融合的过程。无论你是平台方,还是独立电商卖家,核心诉求都集中在以下几个方面:
这些分析工作并非独立存在,而是互相关联、环环相扣。比如,商品结构决定了用户选择,用户行为影响库存周转,库存周转又直接影响资金流和财务健康。只有将各项数据打通,形成完整的分析链条,才能真正实现数据驱动的精细化运营。
商品数据分析让电商运营者从“经验决策”升级为“数据决策”,显著提升业绩和竞争力。 拿最常见的几个应用场景来说:
每一项分析都能产生明确的业务价值。比如,仅仅通过SKU周转率分析,就能帮助一家中小型电商每年节约数十万元的仓储和物流成本。数据分析工具已成为现代电商的标配和核心竞争力来源。
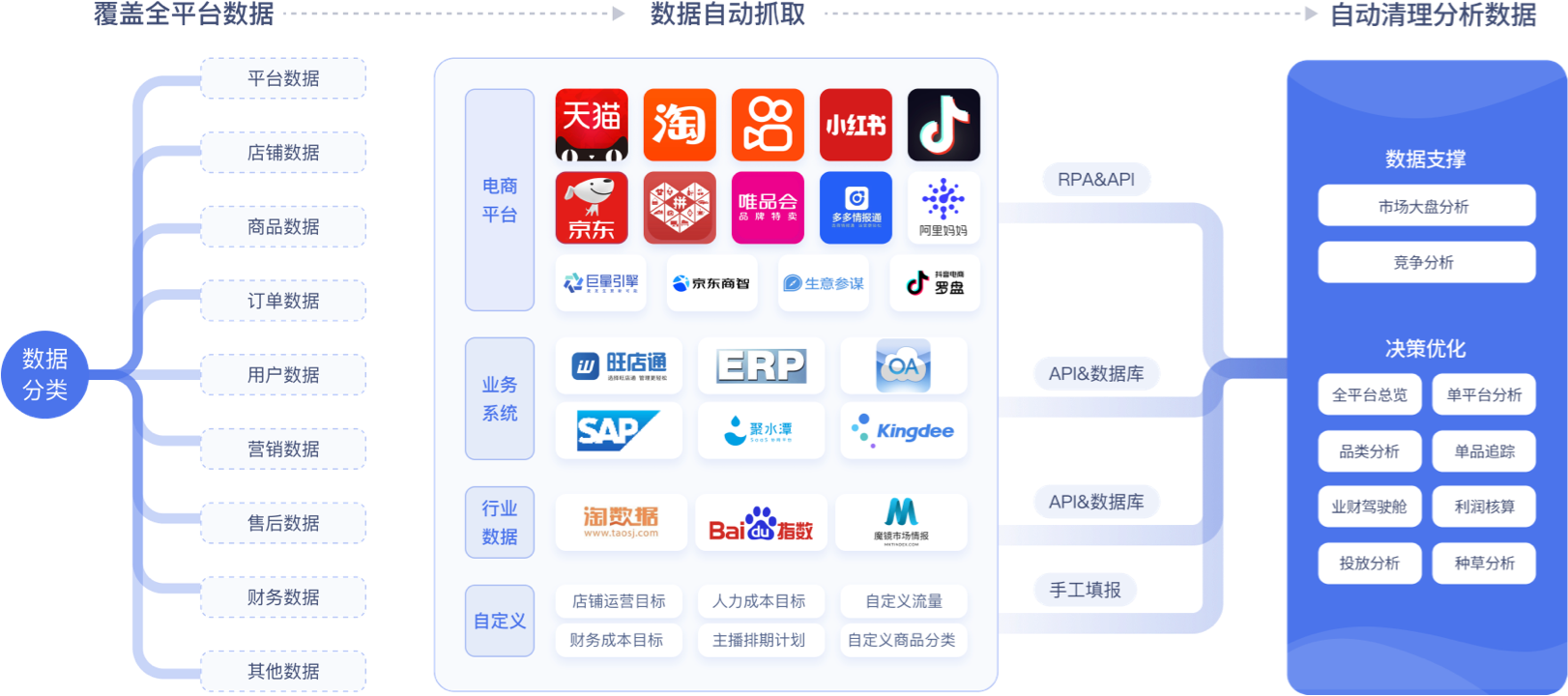
高效、稳定的数据采集,是电商商品分析的第一步。 目前主流的数据采集方式有三种:
实际项目中,常常需要多种方式结合,保证数据的全面性和及时性。下面以Python爬虫为例,给出一个基础的商品信息抓取代码模板:
import requests from bs4 import BeautifulSoup import pandas as pd def crawl_product_list(url, headers): response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, 'html.parser') products = [] for item in soup.select('.product-item'): title = item.select_one('.title').text.strip() price = item.select_one('.price').text.strip() sku = item['data-sku'] products.append({'sku': sku, 'title': title, 'price': price}) return pd.DataFrame(products) headers = {'User-Agent': 'Mozilla/5.0'} url = 'https://example.com/products' df = crawl_product_list(url, headers) print(df.head()) 实际项目中,还需处理反爬、登录、分页、图片下载等复杂场景。对于规模化、自动化的数据抓取,建议结合爬虫框架(如Scrapy)、分布式调度、代理IP池等技术,确保数据源的合规与稳定。
原始采集到的数据,往往存在缺失、重复、异常、格式不统一等问题,必须经过系统的清洗和预处理,才能进入后续分析环节。 下面是常见的预处理步骤和对应的Python实现思路:
典型的Python数据清洗代码如下:
import numpy as np # 缺失值填充 df['price'] = df['price'].replace('', np.nan).astype(float) df['price'].fillna(df['price'].median(), inplace=True) # 日期格式转换 df['created_at'] = pd.to_datetime(df['created_at']) # 去重 df.drop_duplicates(subset=['sku'], inplace=True) 经过清洗后的数据表,结构明确、字段统一、无严重异常,为后续的数据分析和建模打下坚实基础。 这是保证分析结论可靠性的前提,也是很多初学者最容易忽略的关键环节。
销量分析是电商商品数据分析的重中之重,也是运营决策的直接依据。 在实战中,销量分析不仅仅是“哪款卖得多”,更要结合时间、渠道、活动、客户群体等多维视角洞察商品表现。常用的分析指标包括:
Python实现SKU销量和转化漏斗的代码思路如下:
# 假设有订单表orders,包含sku、user_id、order_status、order_time等字段 # 计算各SKU销量 sku_sales = orders.groupby('sku')['order_id'].count().sort_values(ascending=False) print(sku_sales.head(10)) # 计算转化率 views = item_logs[item_logs['event']=='view'].groupby('sku')['user_id'].nunique() adds = item_logs[item_logs['event']=='add_cart'].groupby('sku')['user_id'].nunique() orders = item_logs[item_logs['event']=='pay'].groupby('sku')['user_id'].nunique() conversion = pd.DataFrame({'views': views, 'adds': adds, 'orders': orders}) conversion['view2add'] = conversion['adds'] / conversion['views'] conversion['add2order'] = conversion['orders'] / conversion['adds'] print(conversion.head()) 通过多层次的销量与转化分析,不仅可以精准锁定高潜力爆款,还能及时发现转化瓶颈,为后续的运营策略和资源分配提供数据支撑。
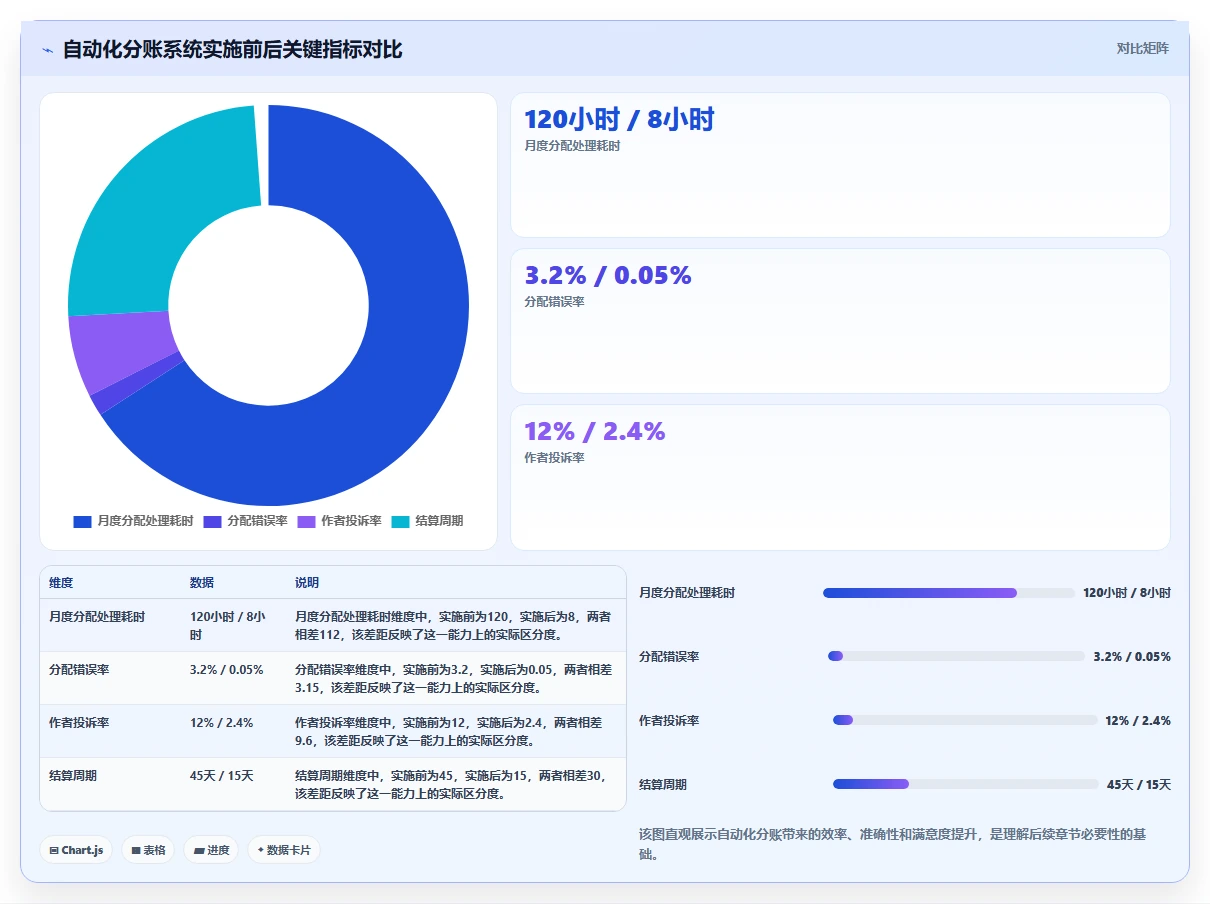
库存管理是电商运营的生命线,库存分析直接关系到资金效率、客户体验和供应链安全。 在电商商品数据分析中,SKU级别的库存动态与周转效率,是所有运营团队必须高度关注的核心指标。常见的分析内容包括:
Python实现库存分析的典型代码如下:
# 假设有库存表stocks,包含sku、stock_qty、last_update等字段 # 当前库存量 sku_stock = stocks.groupby('sku')['stock_qty'].sum().sort_values(ascending=False) # 周转天数 = 库存量 / 日均销量 daily_sales = orders.groupby('sku')['order_id'].count() / orders['order_time'].nunique() turnover_days = sku_stock / daily_sales turnover_days = turnover_days.reset_index().rename(columns={0: 'turnover_days'}) print(turnover_days.sort_values('turnover_days')) # 缺货SKU自动预警 danger_sku = sku_stock[sku_stock < safe_stock_threshold] print("低于安全库存的SKU:", danger_sku.index.tolist()) 高效的库存分析能够显著减少断货损失、降低仓储成本,并推动供应链管理智能化。 电商企业可通过集成类BI工具实现自动化库存分析。例如,九数云BI免费在线试用,支持多平台、多店铺库存与销售自动对接,帮助高成长型卖家精准把控每一个SKU的全生命周期。
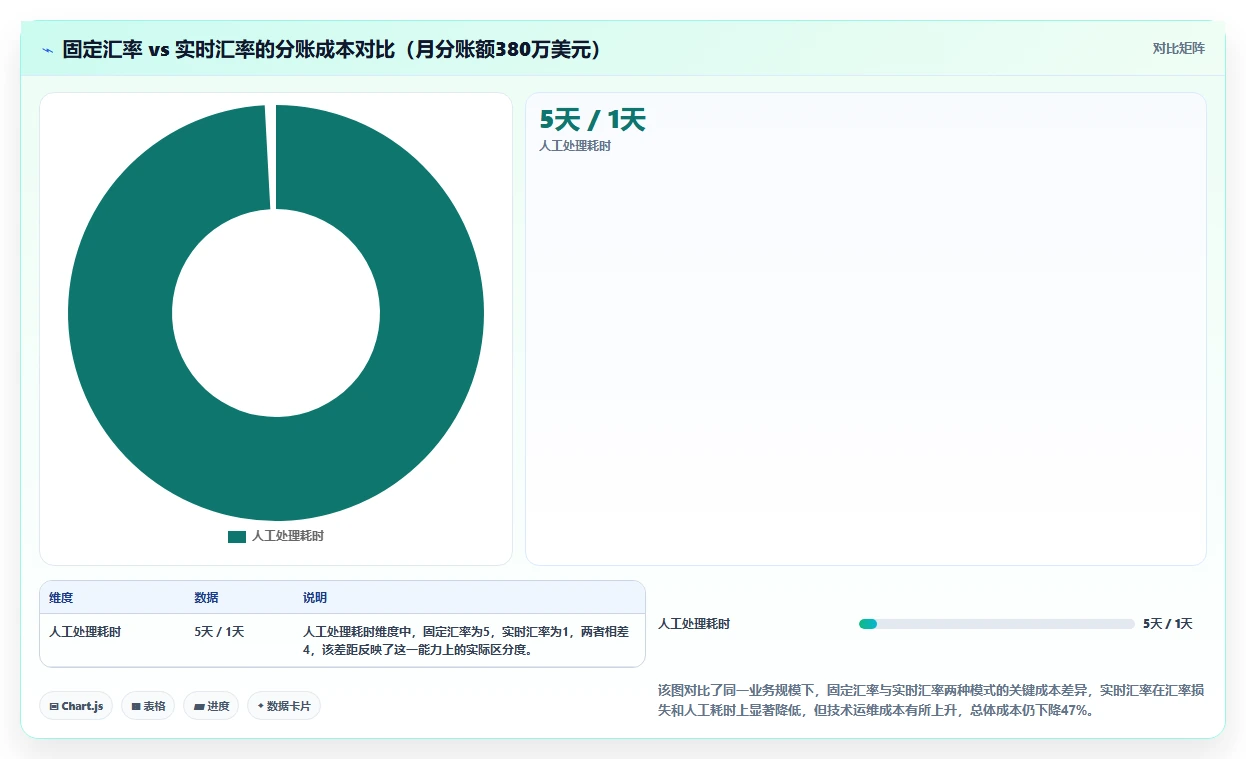
商品财务分析是电商健康运营的底层保障,直接影响企业盈利和持续发展能力。 电商商品数据分析不仅要关注销售额,更要追踪与每一笔订单相关的成本、利润和费用分摊。常见的分析指标有:
Python实现财务分析的代码思路如下:
# 假设有商品成本表costs,包含sku、cost_price、logistics_fee、commission等字段 # 合并订单与成本 order_detail = orders.merge(costs, on='sku') order_detail['profit'] = order_detail['sale_price'] - order_detail['cost_price'] - order_detail['logistics_fee'] - order_detail['commission'] # 计算SKU毛利率 sku_profit = order_detail.groupby('sku')['profit'].sum() sku_sales = order_detail.groupby('sku')['sale_price'].sum() sku_gross_margin = sku_profit / sku_sales print(sku_gross_margin.sort_values(ascending=False)) # 识别负毛利SKU loss_sku = sku_gross_margin[sku_gross_margin < 0] print("异常亏损SKU:", loss_sku.index.tolist()) 通过定期的商品财务分析,电商企业可以及时调整SKU结构、优化定价、控制成本,确保业务高质量增长。 结合自动化BI工具,还能实现多维度财务报表与利润追踪,大幅提升财务管理效率。
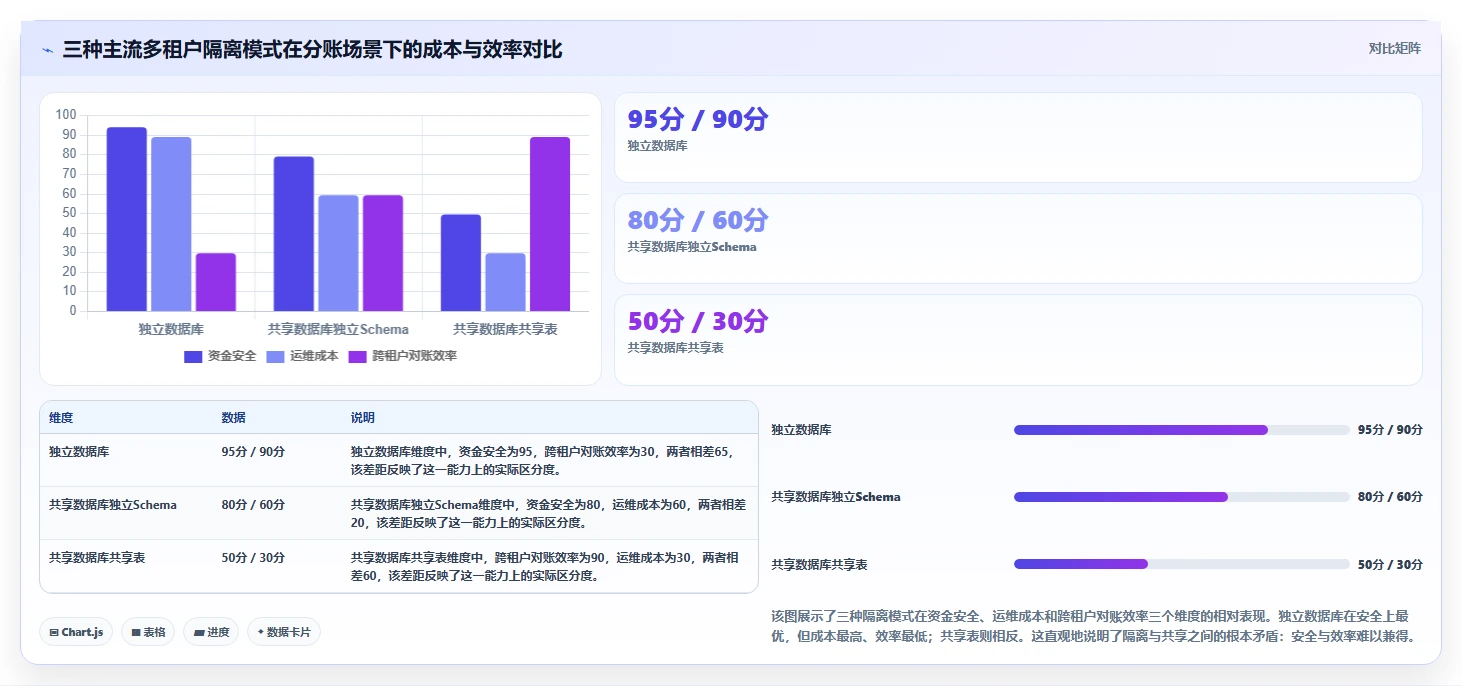
数据分析的最终落地,是将复杂的分析结果以直观、可交互的报表和可视化大屏形式展现,支撑团队协作与高效决策。 传统的Excel手工报表已难以应对电商业务的高频变动和多维需求。Python与BI工具的结合,能够实现自动化报表、实时数据更新和个性化分析展现。常见的数据可视化内容包括:
Python常用的可视化库有Matplotlib、Seaborn、Plotly等。例如,快速绘制SKU销量排名TOP10的可视化代码如下:
import matplotlib.pyplot as plt top10 = sku_sales.head(10) plt.figure(figsize=(10,5)) plt.bar(top10.index, top10.values) plt.xlabel('SKU') plt.ylabel('销量') plt.title('SKU销量TOP10') plt.show() 对于多平台、多店铺、多角色协同的电商企业,建议采用九数云BI等SaaS BI平台,实现跨部门、跨系统的一站式数据对接和报表管理。 九数云BI支持淘宝、天猫、京东、拼多多、ERP等多源数据自动汇总,内置多种销售、财务、库存分析模板,实现数据驱动的敏捷决策与高效协作,助力企业快速成长。
电商网站商品数据分析,早已不是“会写 ## 本文相关FAQs
Python 在电商网站商品数据分析领域绝对是一把多面手。你可以用它来完成数据采集、清洗、分析和可视化,甚至还能自动进行数据监控和预警。最常见的应用场景包括:
这些实操背后的核心,就是利用 Python 强大的数据处理和分析库(如 pandas、numpy、matplotlib、scikit-learn),结合业务数据,做出高效而精细的决策支持。如果你想让数据分析自动化、智能化,Python 是你的不二之选。
想用 Python 采集电商商品数据,最常用的就是爬虫技术。比如 requests + BeautifulSoup 组合,适合静态网页;如果遇到 JS 渲染的内容,可以用 Selenium 模拟浏览器操作。以采集某电商网站商品标题和价格为例,简单代码如下:
import requests from bs4 import BeautifulSoup url = 'https://example.com/products' headers = {'User-Agent': '你的浏览器UA'} response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, 'html.parser') for item in soup.select('.product-item'): title = item.select_one('.title').text price = item.select_one('.price').text print(title, price) from selenium import webdriver driver = webdriver.Chrome() driver.get('https://example.com/products') items = driver.find_elements_by_css_selector('.product-item') for item in items: title = item.find_element_by_css_selector('.title').text price = item.find_element_by_css_selector('.price').text print(title, price) driver.quit() 当然,采集前最好先了解目标网站的 robots 协议和法律合规性要求,合理采集,避免被封禁。数据抓取后,建议及时落地到数据库中,方便后续分析和处理。
pandas 是数据分析领域的“瑞士军刀”,用来处理电商商品数据再合适不过。假设你已经抓取到商品数据并导入了 DataFrame,常见的数据清洗和透视操作有:
import pandas as pd df = pd.read_csv('products.csv') df = df.dropna(subset=['price', 'sales']) # 删除价格或销量缺失的商品 df['price'] = df['price'].str.replace('¥', '').astype(float) # 去掉货币符号并转为数字 pivot = df.pivot_table(index='category', values='sales', aggfunc='sum') print(pivot.sort_values('sales', ascending=False)) # 看各品类销量排名 q_low = df['sales'].quantile(0.01) q_high = df['sales'].quantile(0.99) df = df[(df['sales'] >= q_low) & (df['sales'] <= q_high)] # 去掉极端销量
借助 pandas,不仅能高效完成数据整理,还能一键做出透视分析,快速洞察商品表现。日常运营中,建议定期跑清洗脚本,保持数据新鲜和可靠,为后续的高级分析打好基础。
电商数据分析绝不止于销量和价格。其实,商品层面还可以挖掘出一系列核心指标,帮助企业更精准地洞察市场和用户需求,包括:
这些指标结合用户属性、流量渠道等数据,能极大提升分析的深度和广度。建议搭建数据指标体系,动态追踪和对比,驱动商品运营不断迭代升级。
对于需要高效落地这些多维度分析的电商企业,推荐试用 九数云BI ——专为高成长型电商企业打造的数据分析工具,支持灵活的数据整合与可视化,极大提升分析效率和决策质量。九数云BI免费在线试用
数据可视化是让分析结果一目了然的“终极武器”。Python 社区有很多优秀的可视化工具,最常用的是 matplotlib、seaborn 和 plotly。举个例子,假设你要展示不同品类的商品销量,可以这样写:
import matplotlib.pyplot as plt categories = ['服装', '数码', '家居'] sales = [2000, 3500, 1500] plt.bar(categories, sales) plt.title('各品类商品销量') plt.xlabel('品类') plt.ylabel('销量') plt.show() import seaborn as sns import pandas as pd data = pd.DataFrame({'品类': categories, '销量': sales}) sns.heatmap(data.pivot_table(index='品类', values='销量'), annot=True, cmap='YlGnBu') import plotly.express as px fig = px.pie(values=sales, names=categories, title='品类销量占比') fig.show()
通过这些图表,管理层和运营团队可以快速捕捉趋势和异常,辅助做出科学决策。建议结合多种图表类型,动态展示分析结果,打造数据驱动的运营闭环。